
What algorithm should we use? | Real teams doing AI
When should the question of algorithms come up in AI projects? AI algorithms do a lot of useful things. We look into the basics of algorithms here, what they do, their advantages and drawbacks and consider to what extent they will solve your problem.

Photo by Volodymyr Hryshchenko on Unsplash
When I did my first proto-AI projects in the 00's, I would start from a) OK, I have this data and b) I need to create this feature with it: what kind of algorithm should we use to produce the feature data from the source data?
As we saw in the previous post, it doesn't work quite like that. Still, algorithms do useful things, but what are their advantages and drawbacks?
You're an educated person, so you know that there are four kinds of AI techniques and that it's important to understand the operational differences between these approaches. Each approach is a different tool for a different purpose. Let's review the basics.
Deterministic, or rules-based, algorithms
Rules-based algorithms are explicit analytical statements that, given a predetermined input property, will perform a predetermined action, leading to a predetermined outcome — here, all the knowledge resides in business rules like IF - THEN statements.
This approach is a way for experts to formalize the work that they do, making explicit the implicit logic and knowledge that they use to do tasks, make decisions or produce data, so that it can be automated using the same logic. The advantage here is that the algorithm is completely transparent to humans and can be edited, can draw on any number of sources of explicit knowledge to trigger decisions. Expert Systems are in this category, but so are regular-expression-based annotators, for example.
The problem is that in many cases, a) the decisions made by humans are not as explicit and predictable as we like to think, or b) they rely on too much interpretation and prior knowledge that is either not consciously accessible to experts, too complex to be written up into rules and lookup values or not available as a corpus of data.
Supervised learning algorithms
Supervised learning algorithms learn to figure out the correct expected outcome given an input, by analyzing examples of correct inputs and expected outputs provided to it ahead of time - for instance, it will learn to select the appropriate label for a new item, given a corpus of items of the same type already annotated with labels — here, all the knowledge is in the data.
This approach is a way to use existing data with explicit formal knowledge encoded in it, such as labels, categories, relations, serial values and so on, and have a machine learn to reproduce the output on its own given the types of input. The advantage here is that the machine can parse a very large number of parameters and dimensions to try and fit the rules that it learns to the data it is learning from. That overcomes the problem of scale, complexity or ambiguity of the expert system approach.
The problem is that for all practical purposes it's impossible to edit and review what the machine is actually doing. If it gets things wrong, the only way to influence what the machine will do is to tweak the data and the model configuration, see what happens and develop intuitions about it for the next iteration. You can't decide what the machine is going to do.
Unsupervised learning algorithms
Unsupervised learning algorithms will take any corpus of data and return patterns, groupings, and generally discover properties and structure in the data by trying to replicate it — here, there is no knowledge.
This approach relies on general assumptions about the existence of intrinsic structure in the data and uses the machine to help discover that structure and navigate the data. The advantage is that it requires nothing else than just raw data to run, and, faced with unstructured data it can help a human develop intuitions and generate insights about it.
The problem is that it will generate in and of itself no actual knowledge, and typically a lot of noise. It can be used to suggest similar things, or extract salient things, which may or may not make sense to humans. It is an investigatory approach, and relies on a lot of prior assumptions to be useful. But it can also help you develop better assumptions, check them and gradually either build a set of interpretation rules for your data, or annotate it as you go to eventually have a supervised learning training set.
One thing I've noticed is that in most of the so-called unsupervised learning projects that I've seen that do anything useful, it's always quite easy to identify that there are always critical pieces of supervision somewhere. In other words, in my opinion, the operational value of the distinction between supervised and unsupervised is not all that obvious, even to practitioners. It is a way to categorize algorithms into types, but it doesn’t really tell you anything useful about the work that you need to do on the data to get useful output.
Humans
Humans are great at dealing with ambiguity, using prior knowledge to produce new knowledge, recognizing what things are and relating similar things. If you have the time and money, they're a great option — here, all the knowledge is on the payroll.
The advantage is that, as a business requirements owner, you don’t need to explain to an engineer how to encode 10 years of experience and 5 years of higher education into an algorithm. It’s quite easy to explain things to humans using language. Unlike AI, a human can be explained things, shown a couple of examples, and reproduce the activity. They have an extrapolation and generalization engine in their head that is literally second to none.
The drawback is that humans most of the time don't really know exactly why they do what they do, have a fuzzy property of subjectivity, and giving the same task to several humans will yield increasingly different results with the degree to which the task is interpretative. In other words, as black boxes go, human brains are pretty high on the scale.
So, are we doing machine learning or what?
Different algorithms are available to your pipeline to perform different tasks.

In the end, the only question that matters is this: what data do we need where in the application to support the features, and what are the gaps with what we have? Once you understand these gaps, then you can analyze what algorithms to use to close each of them.
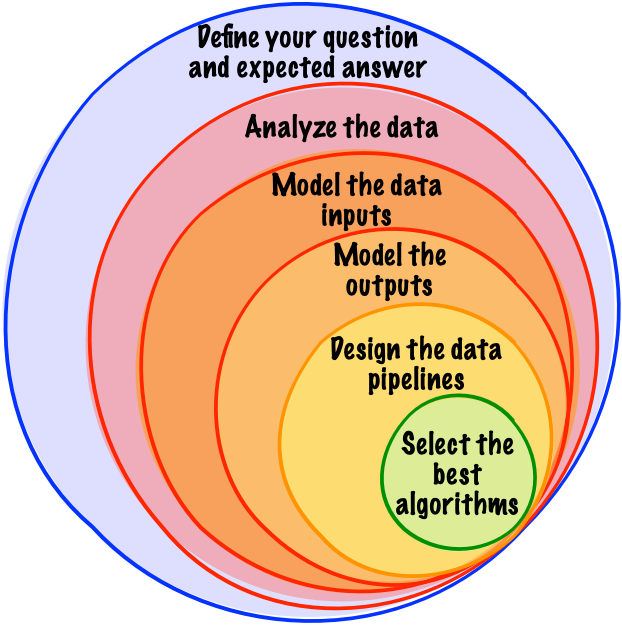
Don't worry about algorithms. The solution to your problem is not the algorithm. As is always the case, 90% of the solution to your problem is a very clear description of your problem.
"If you tell me precisely what it is a machine cannot do, then I can always make a machine which will do just that."
— John Von Neumann
If anyone asks what algorithms we should use on the project, ask them if they can describe exactly what step of the pipeline it is for and exactly how they expect the input and output to correlate. If they can’t, then it’s too early to decide.
Algorithms are just part of the toolkit to generate or process the data. Once you analyze your data and understand what needs to be done to it, algorithms will sort themselves out.
Comments