
Is the data what you think it is? | Real teams doing AI
Public hype about AI algorithms doing everybody's work for them, doomsday predictions of AI taking over humanity, AI is talked about as if the algorithms had agency. They don't. AI doesn't do what a lot of people pretend it does.

Photo by Susan Yin on Unsplash
I took me years to realize that when the AI team inevitably asks the team "where's the training data", there's a set of critical flawed assumptions in that question that the team needs to get on the table asap to get rid of them.
The assumption is this: that the business owners know what data they need in the application, that the experts know how to produce it and, last but not least, that most of the AI team's work will consist in getting labelled data from the experts, and then finding the best performing learning model to replicate the output at scale.
The fact is, I have never seen a project like this, at least that produced any value in the normal world.
For instance, a few years ago, we wanted to create a model to learn how to label a large set of documents with detailed subject information. The training data was a corpus of already extensively labelled articles, that had been labelled over many years by experts. This being machine-learning and AI and all, we wanted to find the best model to train on the data that experts had labelled, and use that model to label new documents. This would help us build subject-monitoring features in the application.
Cut to many months later, and we had, depending on how you count, at least 5 different models each dealing with a very narrow piece of the labeling logic, such as NLP for cleaning up label text, label clustering based on label values, document clustering based document text, some aditional cluster cleanup combining both, deterministic and "unsupervised" (I put scare quotes here because I don't believe in unsupervised algorithms – at least it doesn't mean what people say it means) algorithms to build label relationships from the document clusters, and so on. And we were still quite far from our original goal.
Yet, at the beginning, when we looked at our labelled documents, based on a naive understanding of what deep learning can do, it seemed to make sense that some model could be trained to learn all this stuff.
What I learned from that is that, even for a simple document labelling task, the question "where is the training data?" is not the operative question.

The operative question is "what is the sequence of steps that my data needs to go through before it can yield the information that my application needs?". I'll talk more in detail about "What's a model" in a later series, but for now let's point out that building that sequence of steps, with well-defined inputs, outputs and conditions, is where the real innovation, hard work and value are.
Even if we are only using machine-learning in our AI, I realized we were in fact building rules. The required depth of data analysis and process-chaining in the data pipeline was almost identical to building a rules-based algorithm. ML models making up processing steps of the algorithm didn't eliminate the need for a sequence of well-defined inputs, processing and outputs.
What should we do with the data?
In my experience:
1.there are three kinds of data:
- data that already contains the useful and usable information, where teams just need to retrieve, combine, calculate, run stats, filter and display it, build awesome UX around it, personalize on it, that sort of thing - typically, financial data, simple topical labelling, back-office information and some user activity and profile data;
- data that has the information in there somewhere, but it's unstructured, derivative, hidden, implicit, messy, noisy, unreliable, incomplete, or otherwise unusable, and the goal is to use AI techniques to make sense of it, to extract useful interpretable data from this mess - typically, application trace logs, sensor data, data archives and excel files, some user activity data;
- text.
2.there are three kinds of things that you can do with data:
- run statistics to know what's actually happening;
- interpret it to understand why things happen;
- predict it to anticipate events.
All of these can help make better decisions.
When I started working with AI and believing that I understood what AI algorithms did, I kept running into a problem that I couldn't put my finger on, where I couldn't reconcile what I understood about them with what the AI experts that I was working with were saying.
What I eventually understood is that a key point of confusion in multidisciplinary teams trying to do AI is the assumption that my AI-dependent feature is doing something in list 2 above (eg interpret data) using source data from list 1 (eg some trace data). The job of the AI team would then be to figure out what algorithm to use on 1 to deliver 2.

It turns out that it's not. One of the key misconceptions that reading general information about AI and data will expose you to, is the confusion between what the algorithms do and what the feature does that is useful to users.
For example, on one hand we talk about predictive AI features, to predict what could happen, and on the other there are predictive algorithms. When data scientists talk about predictive algorithms, however, they don't actually talk about what you mean as a regular person when you say "predict".
In the world of AI algorithms, everything is about predicting things. But the thing making the human-facing useful prediction is not the predictive algorithm. What a predictive algorithm does is simply to predict a value given an input. It doesn't predict what will happen that matters to you. It predicts, for instance, that given an image of a dog, it's likely that a human would assign it the label "Dog", or that given a series of values, it's likely that the next value will be in range [x-y]. That's what so-called predictive algorithms, whether convolutional neural networks, Monte Carlo simulations or any other, do. They use historical data to guess how likely certain values are to appear given certain inputs and assumptions. They have an extremely narrow focus like this.
{kind=link}
Yet, when humans talk about predictive AI, they mean something completely different. They expect the machine to analyze lots of complex data and reason its way to giving an answer to a predictive question. Such as "Will Joe Biden win the election?".
Take FiveThirtyEight's election prediction application.
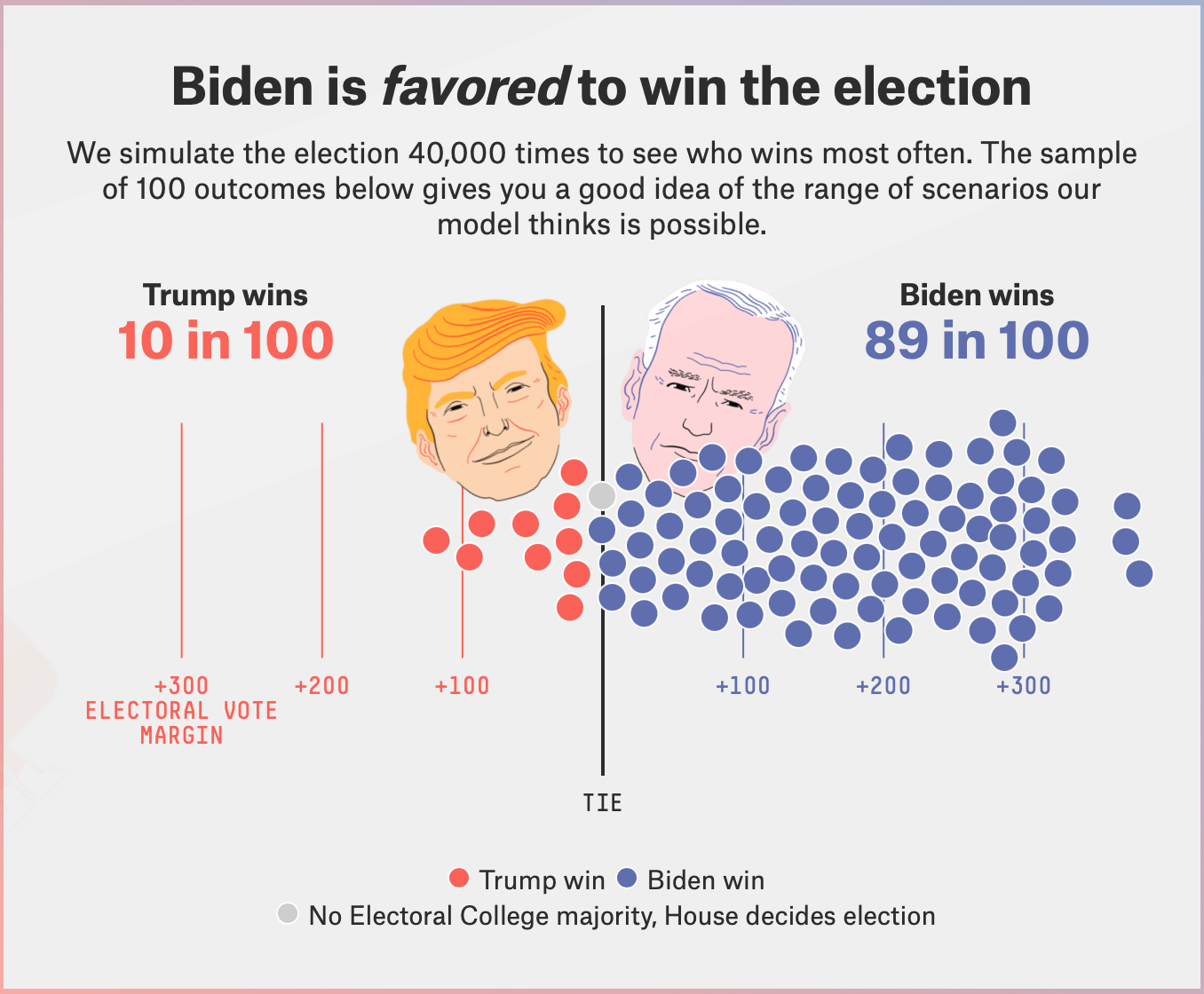
One thing you know for sure, is that it's not just feeding a training model with historical presidential election results and expecting it to predict the next one. No, it does a very large set of very different things, the complex design of which is based on human analysis of what factors are likely to conspire to determine an election. That analysis itself relies on other algorithms and unsupervised data discovery techniques, which will iteratively help humans develop insights about the process. While the model itself, once it's published, does indeed take a lot of data, crunch it, and produce an answer, the real work is done by many humans making a lot of informed hypotheses and decisions about what data determines how elections turn out in order to build the models involved in computing the answer.
In the normal real world that I know of business initiatives (some PhD paper somewhere at the bleeding edge probably says otherwise), any given stand-alone algorithm can only output one type of value given one type of input. These values can be complex objects, like arrays, matrices or graphs, of course, but the key thing to understand here is that any one algorithm only does one useful thing. In other words, there has to be a relatively obvious, fairly simple, even if implicit, straightforward and meaningful relationship between the given input and the expected output of every single step of the algorithm pipeline.
The hard work is in answering the question "what the hell are we really asking the machine to to here, exactly?" in excruciating detail.
The most important first milestone that needs to be reached in AI initiatives, is for the whole team to understand the meaning of the relationships between all the available inputs in the data and all the expected outputs along the pipeline, one at a time.
OK, but what algorithm should we use, anyway?
So now you've made sure that the team understands the data and what needs to be done to it, you still have to chose algorithms to process it, don't you?
The next post will be a quick review of what AI algorithms can be and we'll start to talk about the role that they play. If you haven't already, subscribe below to receive it in your inbox next week and/or to leave comments or questions on this blog.
Comments